Why Embeddings Matter in AI and Large Language Models
Embeddings have become the unsung heroes of artificial intelligence, particularly in the explosive growth of Large Language Models (LLMs). These numerical representations transform raw data—be it text, images, or even audio—into vectors that machines can manipulate with mathematical precision. Without embeddings, the sophisticated capabilities of models like GPT-4 or BERT would be severely limited, as they enable AI to understand context, similarity, and relationships in a way that echoes human cognition. This article delves deeply into the world of embeddings, exploring their mechanics, historical evolution, critical importance, applications, challenges, and future trajectories. By the end, you'll grasp why embeddings are not just a technical detail but the foundational "language" that powers modern AI.
Checkout on linkedin
The Fundamentals: What Are Embeddings?
At its core, an embedding is a dense vector in a high-dimensional space that captures the essence of data points. For text, this means converting words or sentences into arrays of numbers where semantically similar items are positioned closer together. Imagine a vast coordinate system where "cat" might be represented as [0.2, -0.5, 0.7, ...] and "kitten" as [0.3, -0.4, 0.6, ...], making their vector distance small, while "car" is far away.
This contrasts with older methods like one-hot encoding, which creates sparse vectors without capturing meaning—e.g., "cat" as [1, 0, 0, ...] and "dog" as [0, 1, 0, ...] with no inherent relationship. Embeddings, however, preserve semantic information through learning from data patterns. In LLMs, embeddings are contextual, meaning they adapt based on surrounding content, allowing the model to differentiate polysemous words like "bank" in financial or geographical contexts.
To illustrate, consider this visualization of words in a vector space:

Such representations enable operations like vector arithmetic: the vector for "king" minus "man" plus "woman" approximates "queen," demonstrating captured analogies. Embeddings aren't limited to text; they extend to images (via CNNs like ResNet) and other modalities, creating a unified numerical language for AI.
A Historical Perspective on Embeddings
The journey of embeddings traces back to the 1950s with early information retrieval systems, but they gained traction in the 2010s with Word2Vec, introduced by Tomas Mikolov at Google in 2013. Word2Vec used shallow neural networks to learn static embeddings from large corpora, revolutionizing NLP by enabling tasks like sentiment analysis and translation with unprecedented accuracy.
The 2010s saw evolutions: GloVe (Global Vectors) from Stanford in 2014 incorporated global co-occurrence statistics, improving on Word2Vec's local context focus. Then came the transformer era in 2017 with Vaswani et al.'s "Attention is All You Need," paving the way for contextual embeddings in models like BERT (2018) and GPT (2018 onward). These dynamic embeddings consider entire sentences, marking a shift from static to adaptive representations.
In the 2020s, multimodal embeddings emerged, integrating text, vision, and audio—think CLIP (2021) from OpenAI, which aligns image and text embeddings for zero-shot learning. Today, embeddings underpin trillion-parameter models, with advancements in efficiency and domain-specific fine-tuning.
Here's a timeline highlighting key milestones:
This progression underscores embeddings' role in AI's maturation from rule-based systems to data-driven intelligence.
How Embeddings Function in LLMs
In LLMs, embeddings start with tokenization, breaking input into subwords or characters, then mapping them to vectors via an embedding matrix—a trainable layer in the neural network. Positional encodings, like sinusoidal functions or Rotary Positional Embeddings (RoPE), add sequence information since transformers lack inherent order awareness.
The self-attention mechanism then processes these embeddings, computing weighted sums based on query, key, and value vectors derived from them. This allows the model to focus on relevant parts, enhancing contextual understanding. Training involves pre-training on massive datasets to learn general patterns, followed by fine-tuning.
For a visual breakdown:

This process compresses high-dimensional data into manageable forms, enabling efficient computation even on vast scales.
The Core Importance: Why Embeddings Matter
Embeddings are indispensable because they bridge the symbolic world of human data and the numerical realm of machines. They enable semantic search by measuring cosine similarity between vectors, far surpassing keyword matching. In LLMs, they reduce hallucinations by grounding responses in learned representations.
Efficiency is another key: dense vectors (typically 300-1536 dimensions) allow scalable processing, vital for real-time applications. They also facilitate transfer learning, where pre-trained embeddings boost performance on new tasks with minimal data.
Moreover, embeddings capture nuances like sentiment and intent, powering personalized AI. Without them, AI would revert to brittle, rule-heavy systems incapable of handling ambiguity.
Real-World Applications
Embeddings shine in diverse domains. In Retrieval-Augmented Generation (RAG), user queries are embedded and matched against vector databases like FAISS or Pinecone to retrieve relevant documents, augmenting LLM outputs with factual accuracy.
Visualize RAG in action:
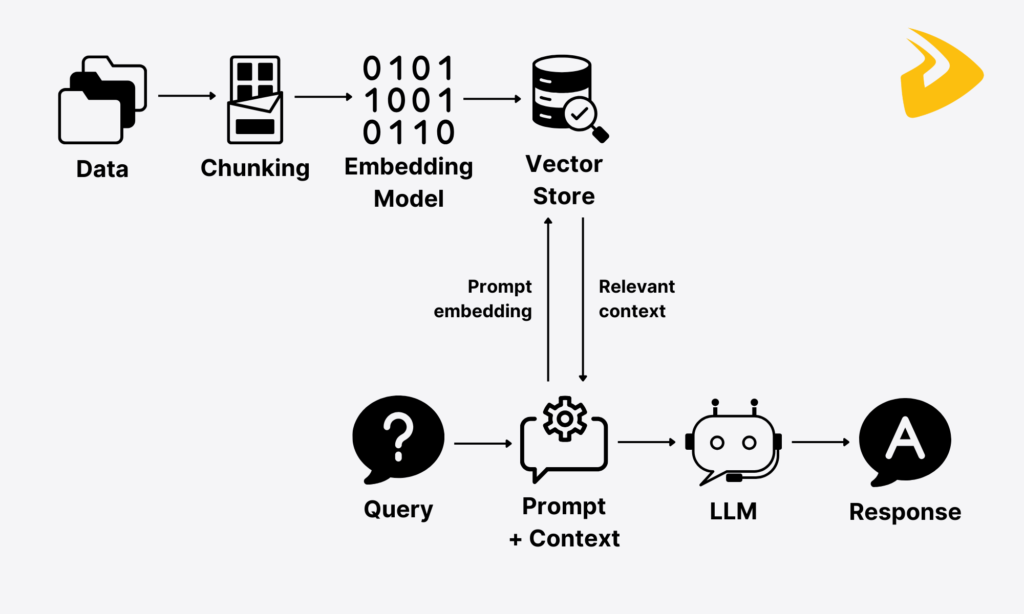
Recommendation systems, like Netflix's, use embeddings to model user preferences and content similarities. In healthcare, they analyze medical texts for drug discovery or patient similarity matching.
Multimodal applications, such as image captioning or visual question answering, leverage joint embeddings for cross-domain tasks. For instance:

These uses demonstrate embeddings' versatility in driving innovation.
Challenges and Limitations
Despite strengths, embeddings aren't flawless. Bias in training data can propagate, leading to skewed representations—e.g., gender stereotypes in word associations. Computational demands are high; generating embeddings for large datasets requires significant resources.
Handling rare words or out-of-vocabulary terms remains tricky, though subword tokenization mitigates this. In multilingual settings, embeddings may underperform for low-resource languages.
Scalability issues arise in vector databases, where indexing billions of embeddings demands advanced techniques like HNSW (Hierarchical Navigable Small World).
Future Directions
The future of embeddings is bright, with trends toward more efficient, multimodal, and domain-specific models. Sparse embeddings could reduce dimensions without losing information, aiding edge devices.
Advances in quantum computing might accelerate embedding computations, while ethical AI focuses on debiasing techniques. Integration with knowledge graphs could enhance reasoning capabilities.
As AI evolves, embeddings will likely become even more integral, enabling agentic systems that reason across modalities seamlessly.
Conclusion
Embeddings are the bedrock of AI and LLMs, translating complex data into actionable insights. From their humble beginnings to powering today's generative marvels, they embody the fusion of mathematics and intelligence. As we push AI boundaries, understanding embeddings equips us to harness their full potential, fostering innovations that reshape industries and societies. In a world increasingly reliant on AI, embeddings ensure machines don't just compute—they comprehend.
References
LLM Embeddings Explained: A Visual and Intuitive Guide
By Hesamation (Hugging Face Space). Published: March 27, 2025.
https://huggingface.co/spaces/hesamation/primer-llm-embeddingEmbeddings 101: The Foundation of LLM Power and Innovation
By Data Science Dojo. Published: August 17, 2023.
https://datasciencedojo.com/blog/embeddings-and-llm/What Are LLM Embeddings? A Simple Explanation for Beginners
By Aisera. Published: March 21, 2024.
https://aisera.com/blog/llm-embeddings/An Intuitive Introduction to Text Embeddings
By Stack Overflow Blog. Published: December 1, 2025.
https://stackoverflow.blog/2023/11/09/an-intuitive-introduction-to-text-embeddings/LLM Embeddings — Explained Simply
By Sandi Besen (AI Mind). Published: July 24, 2023.
https://pub.aimind.so/llm-embeddings-explained-simply-f7536d3d0e4bLLMs are Also Effective Embedding Models: An In-depth Overview
By Various Authors (arXiv). Published: December 16, 2024.
https://arxiv.org/html/2412.12591v1What are LLM Embeddings?
By Iguazio. Published: July 29, 2024.
https://www.iguazio.com/glossary/llm-embeddings/How Embeddings Extend Your AI Model's Reach
By Microsoft Learn (.NET). Published: May 28, 2025.
https://learn.microsoft.com/en-us/dotnet/ai/conceptual/embeddingsWhat are LLM Embeddings: All you Need to Know
By Neptune.ai. Published: November 6, 2025.
https://neptune.ai/blog/what-are-llm-embeddingsEmbeddings: The Language of LLMs and GenAI
By QuantumBlack, AI by McKinsey (Medium). Published: October 4, 2023.
https://quantumblack.medium.com/embeddings-the-language-of-llms-and-genai-b74c2bef105aEmbedding Models Explained: The Reason AI Can ‘Read’ and ‘Listen’
By ConfidentialMind. Published: September 12, 2024.
https://confidentialmind.com/blog/embeddings-and-llmsHow Do Embeddings Work in LLMs?
By Nilesh Barla (Adaline Labs). Published: April 15, 2025.
https://labs.adaline.ai/p/how-do-embeddings-work-in-llmsEmbeddings: What They Are and Why They Matter
By Simon Willison. Published: October 22, 2023.
https://simonwillison.net/2023/Oct/23/embeddings/Understanding Embedding Models in the Context of Large Language Models
By Edgar Bermudez (Medium). Published: January 28, 2025.
https://medium.com/about-ai/understanding-embedding-models-in-the-context-of-large-language-models-02da706ee9b3Understanding LLM Embeddings: A Comprehensive Guide
By IrisAgent. Published: May 16, 2024.
https://irisagent.com/blog/understanding-llm-embeddings-a-comprehensive-guide/Embedding of LLM vs Custom Embeddings
By Stack Overflow. Published: May 1, 2024.
https://stackoverflow.com/questions/78420498/embedding-of-llm-vs-custom-embeddingsWhat is Embedding? - Embeddings in Machine Learning Explained
By AWS. Publication date not specified.
https://aws.amazon.com/what-is/embeddings-in-machine-learning/Add AI Services to Semantic Kernel
By Microsoft Learn. Published: May 22, 2023.
https://learn.microsoft.com/en-us/semantic-kernel/concepts/ai-services/How Can Text Embeddings Be Used by LLMs Like ChatGPT?
By GenAI Stack Exchange. Published: July 31, 2023.
https://genai.stackexchange.com/questions/200/how-can-text-embeddings-be-used-by-llms-like-chatgptVector Embeddings Are a Dead End, Right?
By Reddit (r/OpenAI). Published: August 20, 2023.
https://www.reddit.com/r/OpenAI/comments/15wwglc/vector_embeddings_are_a_dead_end_right/